Machine Learning Operations(MLOps) is one of the most important disciplines to have emerged in modern AI-driven organizations. As organizations increasingly rely on machine learning (ML) and deep learning to automate decisions, personalize user experiences, detect anomalies, and optimize internal processes, they face a new set of operational challenges: How to build scalable ML systems? How can we keep them reliable and update them continuously without causing any issues?
MLOps has the answer.
MLOps practices automate and simplify ML workflows and deployments. It is an ML culture and practice that unifies ML application development (Dev) with ML system deployment and operations (Ops). Organizations utilize MLOps to automate and standardize processes, including model development, testing, integration, release, and infrastructure management, throughout the ML lifecycle.
This article explores MLOps in detail, and explains what MLOps is, why it matters, how it works, and how organizations can implement it successfully, along with the latest trends shaping the field today.
Why MLOps Exists?
Traditionally, software engineering has established practices over several decades that include version control, automated testing, continuous integration, monitoring, rollbacks, configuration management, and other best practices. With these practices, organizations can ship stable products quickly and reliably.
- ML models learn from data and not just code.
- As data changes over time, this means the model’s behavior also changes.
- Models need to be retrained, sometimes subtly, sometimes dramatically.
- ML systems need feature pipelines, GPU-accelerated training, experiment tracking, and special monitoring.
- The infrastructure required for deploying models differs from standard application servers.
These challenges gave rise to a new discipline: MLOps, a combination of machine learning, data engineering, and DevOps.
MLOps Explained
MLOps (Machine Learning Operations) is a discipline that encompasses a set of practices, tools, and cultural principles designed to automate and streamline the end-to-end lifecycle of machine learning models, from data collection to deployment and ongoing management.
MLOps applies the principles of DevOps to the ML lifecycle, ensuring models are reliable, scalable, and deliver continuous value by improving collaboration between data scientists, ML engineers, and IT operations.
MLOps Basics – Key Principles
MLOps streamlines the entire lifecycle of ML models by integrating machine learning and operations. MLOps supports several key principles that are crucial for effective management of ML projects and ensuring continuous improvement:
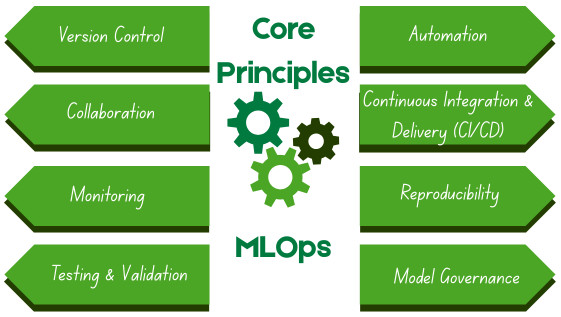
- Version Control: Changes to data, code, and models are tracked and managed using version control. It allows comparison of performance, reproducibility of results, and rollback to previous versions.
- Automation: The entire ML lifecycle, from data preparation and model training to deployment and monitoring, is automated. Automation reduces manual errors, improves efficiency, and enables faster iterations.
- Collaboration: The gap between data science and IT is narrowed by establishing a common framework that enables different teams to work together effectively. Collaboration facilitates seamless interaction among data scientists, ML engineers, and operations teams. It ensures alignment throughout the ML lifecycle and effective communication with stakeholders.
- Continuous Integration and Delivery (CI/CD): DevOps’ CI/CD methodologies are incorporated to create a continuous assembly line for ML models, enabling faster, reliable, and more frequent updates. CI/CD automates building, testing, and deployment of ML models.
- Monitoring: Models in production should be continuously monitored to detect issues such as data drift (changes in data) and concept drift (changes in the relationship between variables), ensuring that performance doesn’t degrade over time.
- Reproducibility: MLOps employs practices such as defining infrastructure as code and tracking experiments to ensure that the entire process is thoroughly documented, version-controlled, and reproducible. Irrespective of the execution environment, identical results are generated from identical inputs.
- Testing and Validation: The correctness and efficiency of the MLOps pipeline and the model are ensured using testing and validation. Approaches employed include data validation, unit testing, integration testing, and model evaluation to identify and resolve issues promptly.
- Model Governance: MLOps ensures compliance with regulations, organizational policies, and ethical guidelines, including aspects such as fairness, transparency, and accountability of ML models.
In essence, MLOps makes ML a repeatable, scalable, and measurable process rather than an ad-hoc research effort.
The Machine Learning Lifecycle (and Where MLOps Fits)
The ML lifecycle consists of several stages depicted below. MLOps overlays structure and automation at each stage.
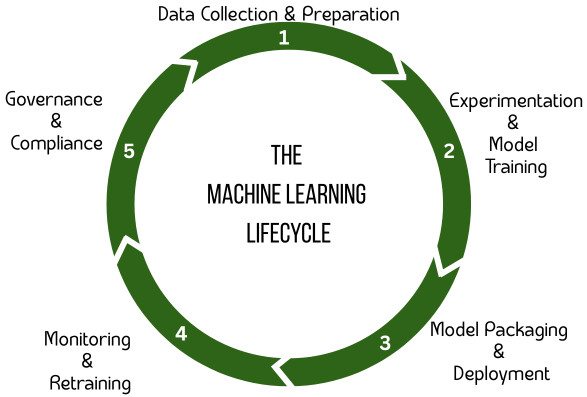
1. Data Collection and Preparation
The machine learning lifecycle begins with data preparation. Data of different types is retrieved from various sources, and activities such as aggregation, duplicate removal, and feature engineering are performed. Data is validated, and quality checks are performed on it in addition to storing datasets in versioned repositories. Metadata tracking is also performed for datasets.
Tools such as Kafka, Spark, Airflow, dbt, Feature Stores, Delta Lake, and BigQuery are utilized in this stage.
2. Experimentation and Model Training
The prepared data is then used to train and validate the ML model. Data scientists conduct numerous training experiments at this stage. MLOps ensures experiment reproducibility, hyperparameter tracking, model lineage (what data and code created what model), automated model evaluation, and scalable, distributed training.
In this phase, tools such as MLflow, Weights & Biases, Vertex AI, SageMaker, and Databricks are utilized.
3. Model Packaging and Deployment
In this stage, the model is packaged and deployed for the user as REST API endpoints, batch pipelines, edge devices, embedded services, or streaming inference.
MLOps handles model registry, CI/CD pipelines, containerization, canary releases, and A/B testing.
The deployment phase utilizes Docker, Kubernetes, Seldon, KServe, BentoML, or FastAPI.
4. Monitoring and Retraining
Once deployed, models must be continuously monitored and maintained. In this phase, MLOps covers data drift, concept drift, prediction bias, latency, throughput, and feature abnormalities.
Tools such as Prometheus, Grafana, Evidently AI, Arize, WhyLabs, and Fiddler AI are utilized in this phase.
5. Governance and Compliance
This is the phase to ensure the model complies with policy guidelines and standards. This includes model explainability, dataset lineage, fairness testing, access control, and human review loops.
In this phase, MLOps enables a complete audit trail, which is essential for responsible AI.
Levels of MLOps Maturity
MLOps maturity is typically described by several levels, ranging from “No MLOps” to “Full MLOps.” While some models simplify maturity to fewer levels, such as Google’s three-level model (manual, automated training, and full automation), others focus on stages like initial, repeatable, reliable, and scalable, as in Amazon’s model.
There are four levels of MLOps implementation, depending on the automation maturity within your organization.
Level 0: Manual ML or No MLOps
Level 0 is characterized by manual ML workflows and a data-scientist-driven process for organizations that are just starting with ML systems. Every step at this level is manual, scripts are run locally, and there is no monitoring.
It requires manual switching between steps, and each step is interactively run and managed. Data scientists typically hand over trained models as artifacts that are then deployed by the engineering team on the API infrastructure.
Level 1: ML Pipelines
Level 1 maturity implementation is beneficial for organizations that frequently want to train the same model with new data. MLOps automates the ML pipeline to train the model continuously. In this level, a training pipeline is deployed that runs constantly to serve the trained model. There is limited monitoring and some versioning at this level, making it suitable for small teams.
Level 2: CI/CD Automation
- Fully automated testing, training, and deployment
- Model registry adoption
- Strong monitoring
- Standardized patterns
- Suitable for production ML
- Build the Pipeline: Iteratively try out new modeling and new ML algorithms to ensure experiment steps are orchestrated.
- Deploy the Pipeline: Build the source code and run tests to obtain pipeline components for deployment. The output is deployed as a pipeline with a new model implementation.
- Serve the Pipeline: Serve the pipeline as a prediction service for applications. Collect statistics on the deployed model prediction service from live data. This level acts as a trigger to run the pipeline or a new experiment cycle.
Level 3: Automated CI/CD + Continuous Training (CT)
Some models may skip this level and incorporate the activities in level 2. This is a level demonstrating true MLOps maturity, wherein the system automatically re-trains and redeploy ML models using real-time data and drift detection. Human oversight may be needed.
This level is typically achieved in large, data-intensive companies.
Benefits of MLOps
- Faster Time to Market: MLOps provides a framework for organizations to achieve their data science goals efficiently and more quickly. Automated pipelines reduce deployment time from months to days or even several hours. Automated model creation and deployment, in turn, reduces the time to market.
- Improved Model Quality: With reduced time for model development and deployment using MLOps, teams are able to focus on more strategic work and improve model quality through experiment tracking, validation, and continuous retraining.
- Better Collaboration: MLOps provides a common framework and language for data scientists, engineers, and operations teams, leading to improved collaboration and better knowledge sharing.
- Lower Operational Costs: MLOps lowers operational costs by automating processes that also reduce manual efforts, errors, and downtime.
- Regulatory Compliance: With MLOps, it is easier to audit, track, and ensure models meet business and regulatory requirements, as it creates transparency in the model development process.
- Efficient Model Deployment: MLOps improves model management and troubleshooting in production. Software engineers can monitor model performance and reproduce behavior for troubleshooting. When the model workflows are integrated with CI/CD pipelines, performance degradation is reduced, and the model can maintain quality.
- Greater Scalability: Organizations using MLOps can effectively manage and scale their ML operations to handle large datasets and numerous models.
- Increased Reliability and Accuracy: Models remain accurate and perform well in production through continuous monitoring and automated testing. They also provide the ability to detect and fix issues like data drift quickly.
Challenges in Implementing MLOps
- Organizational Barriers: MLOps requires shared ownership, clear communication, unified workflows, and cross-team alignment to function effectively. This is often challenging as data science, DevOps, and engineering often operate separately.
- Infrastructure Complexity: MLOps systems often require GPUs, orchestrators, data warehouses, CI/CD pipelines, registries, and real-time streaming systems. Arranging this infrastructure can be a daunting task, especially for organizations new to ML.
- Lack of Standardization: ML is still evolving, and practices, including those in MLOps, are not yet universally standardized.
- Data Quality Issues: Maintaining high-quality datasets is challenging and requires automation. Without quality data, models may not be efficient; after all, bad data equates to bad models.
- Monitoring ML: Monitoring software is much easier than monitoring ML. An ML model may produce outputs that look plausible but are subtly wrong.
MLOps Examples – Real-World Use Cases
- Financial Services: MLOps is used in financial services and the banking industry for fraud detection, credit scoring, and risk modeling. The models used have to be updated continuously as fraud patterns evolve.
- Retail and eCommerce: This industry requires real-time inference at scale. MLOps mostly assists in determining dynamic pricing, recommendation systems, and supply chain optimization.
- Healthcare: MLOps can be used in the healthcare industry for patient risk prediction, personalized treatment, or diagnosis algorithms that require strict auditability and explainability.
- Manufacturing: Tasks like predictive maintenance of machines, quality inspection, and demand forecasting are performed efficiently using MLOps in the manufacturing sector. The models used rely heavily on time-series data.
- Autonomous Vehicles: This requires continuous data ingestion and retraining. MLOps is used in autonomous vehicles for decision planning, perception systems, and prediction models.
MLOps Tools and Technology Used
The following table shows a list of various tools and technologies used in MLOps:
| MLOps Function | Tools/Technologies Used |
|---|---|
| Data & Feature Engineering |
|
| Experiment Tracking & Versioning |
|
| Model Serving |
|
| Monitoring & Drift Detection |
|
| Cloud Platforms |
|
Future Trends in MLOps
- LLMOps (Large Language Model Operations): LLMOps is emerging as its own sub-discipline with the rise of large foundation models, encompassing areas such as prompt management, fine-tuning pipelines, LLM observability, and cost optimizations.
- AutoML and Automated Pipelines: Using end-to-end automation will reduce manual training cycles.
- Real-Time MLOps: Various models are being deployed in real-time, requiring streaming architectures.
- Edge MLOps: Edge devices, such as phones and IoT sensors, can utilize MLOps with specialized deployment techniques.
- Responsible AI and Governance: Heightened regulatory requirements are expected for explainability, fairness, bias reduction, and dataset transparency.
Conclusion
For organizations that want to deploy machine learning reliably at scale, MLOps is rapidly becoming a core capability. It successfully bridges the gap between research and production by combining the strengths of data engineering, software engineering, data science, and DevOps into a unified framework.
As AI adoption speeds up and models become more complex, especially the emerging Large Language Models (LLMs), MLOps will continue to evolve into an indispensable discipline for all data-driven enterprises.