Artificial intelligence (AI) systems are now embedded into nearly every aspect of modern technology, from search engines to self-driving vehicles and from fraud detection to conversational agents. As AI systems grow in influence and their use increases, the consequences of errors, vulnerabilities, and blind spots become more significant. Adversarial testing is one of the most effective methods for understanding and strengthening AI robustness.
Adversarial testing is the approach where AI models are intentionally challenged using specially crafted inputs designed to expose weaknesses. These tricky inputs, called adversarial examples, reveal where the model may behave abnormally, unexpectedly, unreliably, or insecurely. Adversarial testing identifies these points of failure early, enabling organizations to develop safer and more reliable AI systems.
This is a comprehensive guide to the adversarial testing of AI, including its understanding, implementation, and benefits from Adversarial Evaluation.
What is Adversarial Testing?
Adversarial testing is the process of evaluating an AI system by feeding it intentionally manipulated or subtly perturbed inputs that are designed to trigger incorrect or undesirable outputs.
- Language models and conversational AI
- Computer vision systems
- Audio and speech recognition systems
- Reinforcement learning agents
- Cybersecurity defense algorithms
The process is also known as red teaming and aims to identify how an AI might fail under unexpected conditions, allowing it to be more robust, reliable, and trustworthy. It can be used to identify flaws in content filters, test for malicious capabilities, and ensure the AI’s safety policies are adhered to.
How does Adversarial Testing for AI Systems Work?
- Simulating Attacks: Adversarial testing simulates potential real-world malicious attacks to test the AI’s resilience and robustness.
- Feeding Misleading Inputs: Specially crafted inputs, known as adversarial prompts, are designed to fool the AI into making errors or producing unintended output.
- Evaluating Performance: The AI model is then evaluated to assess its performance when presented with these challenging inputs, identifying potential security gaps or unsafe behaviors.
Usage Examples
- Content Filters: Large Language Models (LLMs) incorporate content filters, making them more effective. Adversarial testing is used to evaluate the effectiveness of a content filter by attempting to bypass it.
- Capabilities Testing: In this process, the AI model is pushed to determine if it performs tasks it wasn’t intended for, such as generating instructions for illegal activities.
- Self-driving Cars: Adversarial testing helps to identify vulnerabilities in self-driving vehicles by deliberately changing road signs to trick the car’s vision system.
- Surveillance Systems: Surveillance cameras can be tricked into not recognizing a person through subtle changes to their appearance to test if they work as expected.
- Voice Recognition: To ensure voice recognition systems generate correct transcripts, they are confused by an audio attack to create false transcripts.
- Malware Detection: Adversarial testing uncovers scenarios, such as changes to malware signatures, that aim to evade detection by an AI security system.
How Adversarial Testing Differs from Normal Testing?
Adversarial testing differs from traditional software testing in two significant ways:
- Probabilistic Behavior of AI Models: In normal testing, systems follow explicitly programmed rules. If a defect exists, it can be traced back to a part of the code. In contrast, in adversarial testing, machine learning systems operate based on learned statistical patterns, making it more challenging to predict and reproduce failure cases.
- Adversarial Tests are Intentionally Crafted to Break the Model: Unlike regular testing, in which the system is tested by feeding thousands of valid inputs, adversarial testing is performed by intentionally crafting inputs that reveal the blind spots in the system.
Why Adversarial Testing Matters?
Adversarial testing is a proactive and systematic method for uncovering critical weaknesses, blind spots, vulnerabilities, and biases in AI models and cybersecurity defenses that standard testing methods overlook.
- Identifies Hidden Weaknesses and Blind Spots: Using subtle, tricky inputs, adversarial testing confuses the AI, pushing the system to its limits to find unexpected failures and edge cases in contrast to standard testing, which validates that a system works under normal, expected conditions.
- Enhances Security and Prevents Exploitation: Real-world attacks are simulated to identify and address security loopholes in the system before malicious actors can exploit them. This is critical for systems handling sensitive information, detecting fraud, or controlling infrastructure.
- Builds Trust and Reliability: In safety-critical applications such as autonomous vehicles, healthcare, and financial services, users seek AI systems that have undergone rigorous testing and proven to be dependable. Demonstrating the system’s robustness through adversarial testing helps meet regulatory and compliance requirements.
- Uncovers and Mitigates Biases: AI models learn from data fed to them, and that data can contain societal biases. Adversarial testing reveals these hidden biases by testing with diverse data across various demographics and cultural contexts, ensuring the system responds fairly and equitably to all users.
- Informs Better Decision Making and Resource Allocation: Adversarial testing provides insights with objective, fact-based data on the spots where defenses are weakest. Using these insights, organizations can prioritize and allocate resources (technology, budget, staff) to address these spots.
- Ensures Continuous Improvement: Adversarial testing is not a one-time activity but a continuous process that provides constant feedback, allowing developers to retrain models, add new defenses, and adapt their system to stay ahead of emerging threats and vulnerabilities.
Types of Adversarial Testing
Adversarial testing can be categorized based on the level of the tester’s knowledge, the nature of attacks (perturbation), and the domains involved. The classification is as follows:
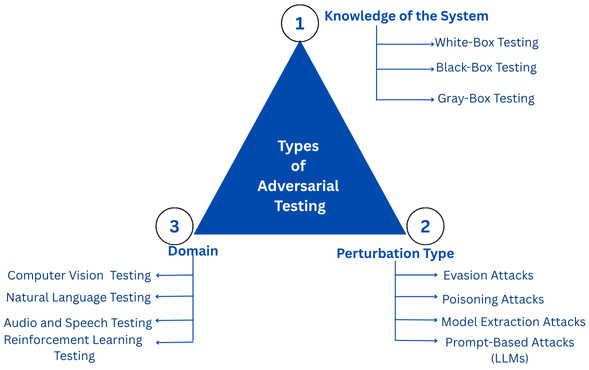
Based on Knowledge of the System
- White-Box Adversarial Testing: In this type of testing, the tester (attacker) has full access to the model architecture, gradients, and weights. This type allows for highly optimized adversarial inputs and is often used in research and internal evaluation.
- Black-Box Adversarial Testing: In black-box testing, the tester only sees inputs and outputs with no access to internal architecture. Black box testing reflects the real-world attacker capabilities.
This type of testing is widely used for deployed AI systems, especially APIs.
- Gray-Box Testing: This is a combination of white box and black box testing. In gray-box testing, the test has partial knowledge of the system. It is common in collaboration between internal QA teams and auditors.
Based on Perturbation Type
- Evasion Attacks: In this type of testing, the inputs are modified during inference to fool the model.
- Poisoning Attacks: Here, malicious data is injected into the model during training to purposely bias it.
- Model Extraction Attacks: In this type of attack, the attacker attempts to steal the target model by making queries and observing the outputs, which can be used to reconstruct a similar model or extract sensitive information.
Model Stealing and Membership Inference Attacks are examples of model extraction attacks.
- Prompt-Based Attacks (LLMs): This is specific to LLMs, and the attacker manipulates prompts by embedding malicious instructions into the prompt to act against its safety guidelines.
Some examples of prompt-based attacks are indirect prompt injection, role-playing attacks, or multi-step jailbreak prompts.
Based on Domain
- Computer Vision Adversarial Testing: This testing is done for the computer vision domain and includes techniques such as pixel-level perturbations, adversarial patches, optical illusions, and physical-world attacks.
- Natural Language Adversarial Testing: Applications in the natural language domain can be tested using paraphrase attacks, synonym substitution, character-level noise, adversarial prompts, and malicious pattern insertion.
- Audio and Speech Adversarial Testing: This type of testing involves waveform-level perturbations, imperceptible audio commands, and background noise attacks.
- Reinforcement Learning Adversarial Testing: This is done by altering environment states or reward signals to mislead agents.
How Adversarial Testing Works?
The entire workflow is shown here:
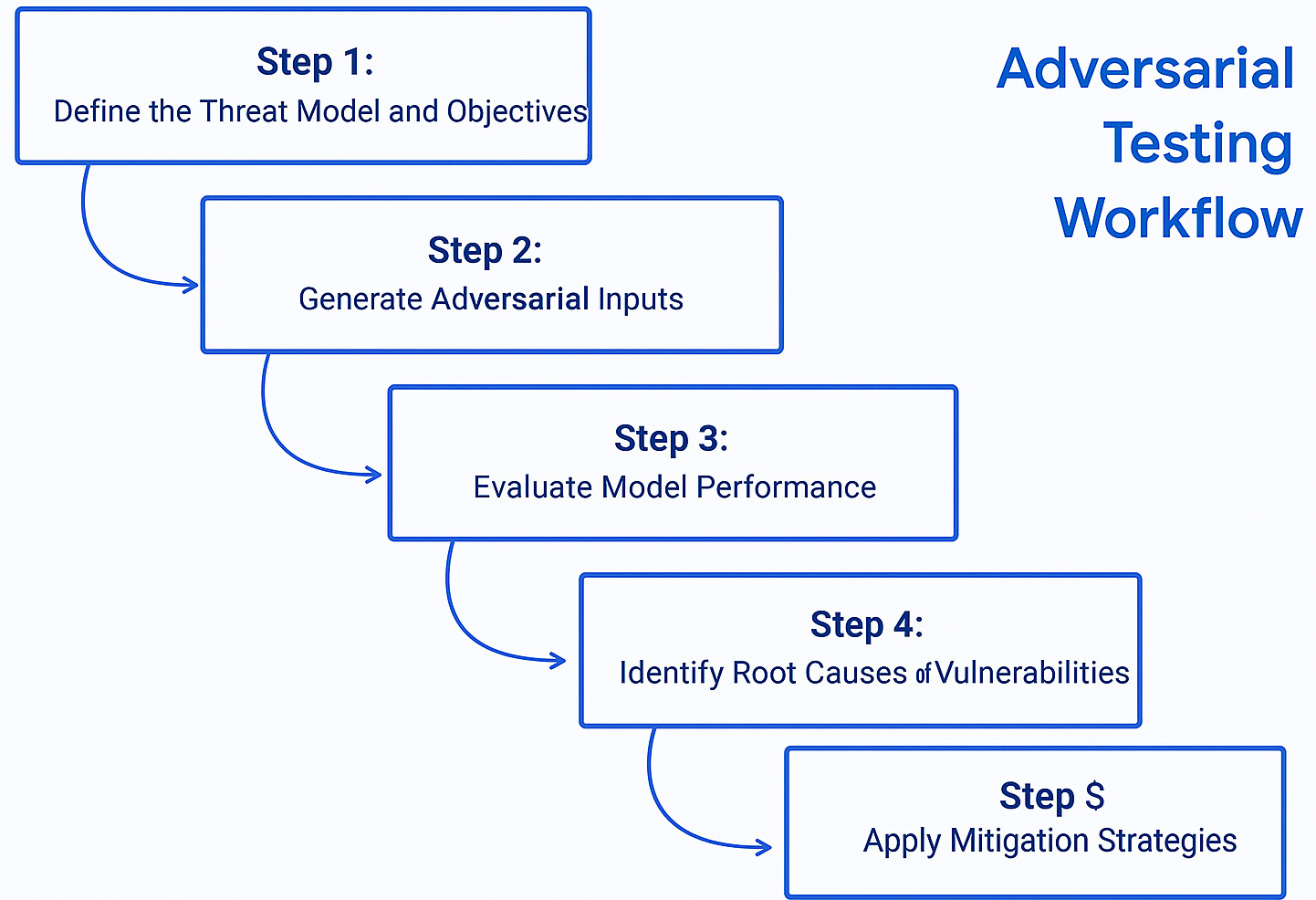
Step 1: Define the Threat Model and Objectives
The process begins by defining the AI’s intended behavior, its “no-go” zones, and potential failure modes. Testers determine use cases and edge cases by considering the common user interactions and unusual ones, and less common scenarios, to ensure broad testing coverage. Potential attack vectors are identified.
- What kind of adversary is assumed?
- What are the constraints?
- What constitutes failure?
- What domain-specific risks exist?
Step 2: Generate Adversarial Inputs
Testers generate inputs designed to challenge the model’s boundaries. This data is specifically selected to cause problematic output and is different from standard training data. Methods used may vary based on testing goals, but often include gradient-based perturbation algorithms and prompt engineering frameworks. Evolutionary or optimization-based methods, and randomized stress testing.
Step 3: Evaluate Model Performance
The AI model is exposed to the adversarial test data, and its outputs are collected and carefully reviewed. Performance is measured across accuracy under attack, safety, and policy adherence (for LLMs), hidden biases, robustness metrics, and attack success rate.
Step 4: Identify Root Causes of Vulnerabilities
Once model performance is evaluated, the root causes of vulnerabilities should be identified. This process includes analyzing failure patterns, identifying weak training data coverage, locating model architecture weaknesses, and examining insufficient guardrails.
Step 5: Apply Mitigation Strategies
After evaluating the model and identifying root causes, based on the findings, developers can retrain the model with the adversarial examples, add new safety filters or safeguards, or refine the core instructions to make the AI more robust. Mitigation may include adversarial training, data augmentation, improved guardrails and filters, prompt defense techniques for LLMs, and better monitoring and fallbacks.
Techniques Used in Adversarial Testing
Several techniques are used in adversarial testing based on the type or domain of the model being tested. Some of these techniques are discussed below:
Gradient-Based Attacks (Vision Models)
- FGSM (Fast Gradient Sign Method)
- PGD (Projected Gradient Descent)
- DeepFool
Gradient-based attacks create adversarial inputs that often look identical to human eyes but cause massive prediction errors.
Prompt-Based Attacks (LLMs)
- Jailbreak Prompts: In this technique, safety mechanisms and content restrictions are bypassed to make the model generate harmful or inappropriate content.
- Indirection Attacks: This technique embeds malicious instructions within another text, for example, text fetched from the web, to carry out malicious instructions.
- Instruction Rewriting: Prompts are rephrased in subtle or deceptive ways to override the system’s intended commands so as to test the model’s robustness and alignment with safety guidelines.
- Chain-of-Thought Manipulation: This technique misleads the model by providing it with false reasoning to lead the model towards unintended conclusions.
Prompt-based adversarial testing is increasingly crucial for evaluating the safety, ethics, and reliability of AI systems.
Black-Box Optimization Attacks
- Evolutionary algorithms
- Bayesian optimization
- Query-based attacks
- Reinforcement-learning-based adversarial searches
Physical Adversarial Attacks
Some adversarial techniques are physical in nature and work beyond digital inputs.
- Adversarial stickers are causing image misclassification.
- Wearable adversarial patches that disrupt facial recognition.
- Road signs manipulation that confuses autonomous vehicles.
Physical adversarial testing ensures robustness in uncontrolled environments.
Data Poisoning Attacks
- Label-flipping
- Backdoor insertion
- Trigger-pattern poisoning
Benefits of Adversarial Testing
- Improved Model Robustness: Adversarial testing exposes weaknesses and blind spots in AI models that traditional QA never sees. Developers can retrain the AI models to fix these vulnerabilities and add safeguards to handle unexpected or subtle inputs. This results in more stable performance, better generalization, and increased reliability in edge cases.
- Enhanced Security Posture: Adversarial testing helps secure AI applications from various attacks, such as prompt injection and jailbreaking, preventing potential misuse such as exposure to sensitive information, data theft, and fraud. It also reduces exploitation risk, helps organizations harden their defenses, and exposes attack vectors early.
- Increased User Trust: Users gain trust in model fairness, ethical behavior, and predictability of the AI model when it behaves safely and reliably under pressure. Transparent and rigorous testing demonstrates due diligence, essential for building user trust and increasing AI adoption in society.
- Regulatory and Compliance Alignment: Adversarial testing helps ensure AI systems adhere to ethical standards and safety policies that are crucial in high-stakes applications like healthcare and autonomous vehicles.
- Uncovering Hidden Biases: Adversarial testing uses diverse and culturally sensitive queries to reveal underlying biases in the training data or model behavior that might not be obvious during normal operation, ensuring fairer and more equitable responses.
Challenges in Adversarial Testing
- Infinite Potential Attack Surface: Many AI models, especially deep learning networks, are highly complex and sensitive to small, often imperceptible changes in input data. Adversaries can craft endless variations in attacks, especially in language models.
- Difficulty of Reproducing Attacks: AI models are closed-source and continuously updated, due to which researchers are unable to reproduce results or track progress against specific vulnerabilities over time. In addition, model behavior is probabilistic, and adversarial attacks may work inconsistently, degrade or vanish after updates, and depend on model version.
All these make it difficult to reproduce attacks.
- Balancing Robustness and Performance: It is difficult to build models that are inherently resilient to adversarial manipulation without sacrificing performance on clean data, as strengthening defenses can sometimes reduce model accuracy, increase training costs, and slow down inference.
- Arms Race Between Attackers and Defenders: The AI field evolves rapidly, and new defenses are constantly being innovated. However, attackers also continuously innovate new techniques, using advanced algorithms and automating to bypass new defenses. This creates an arms race between attackers and defenders, where defenses often lag behind new attack vectors.
- Resource Constraints: Implementing complex adversarial validation and robust defense mechanisms in resource-constrained environments like edge computing and IoT devices is difficult due to limited computational power and memory.
Best Practices for Implementing Adversarial Testing
- Build a Clear Threat Model: Identify who might attack the system, their resources, and their goals so that you can build a clear threat model.
- Evaluate at Multiple Levels: Evaluate models at different levels to include data pipeline, model training, model inference, API-level interactions, and real-world deployment scenarios.
- Combine Automated and Manual Testing: Although automated adversarial generators are powerful, include human creativity by performing manual testing, especially with LLM jailbreaks.
- Maintain Continuous Testing: Perform continuous adversarial testing by performing it after model updates, after data changes, before deployment, and periodically in production.
- Use Domain-Specific Adversarial Tools: Use testing tools that are aligned with AI types, such as vision adversarial frameworks, LLM red-teaming frameworks, prompt fuzzers, and reinforcement learning adversarial simulators.
The Future of Adversarial Testing
- Automated Red Teaming Agents: AI systems will test each other (AI testing AI), identifying vulnerabilities faster than humans can.
- Regulation-Enforced Robustness Standards: Governments are already drafting standards and regulations requiring formal adversarial evaluations.
- More Powerful, Generalized Attacks: Proactive testing will become more crucial as models grow in complexity and attackers find new ways to exploit weaknesses.
- Safer Foundation Models: Future AI models will be pre-trained with adversarial robustness in mind, embedding resilience at the architecture level.
Summary
Adversarial testing of AI is no longer an option, but is a foundational requirement for building safe, trustworthy, and resilient AI systems. By intentionally challenging, misleading, or feeding malicious inputs to AI models, organizations can identify vulnerabilities that standard testing may overlook.
From deep learning image classifiers to reinforced agents and large language models, adversarial testing helps ensure security against exploitation, ethical and safe outputs, user trust and confidence, compliance with emerging regulations, and reliable performance under pressure.
As AI continues to evolve and influence the technical world, adversarial testing is set to play a pivotal role in shaping the future of responsible, safe AI deployment.